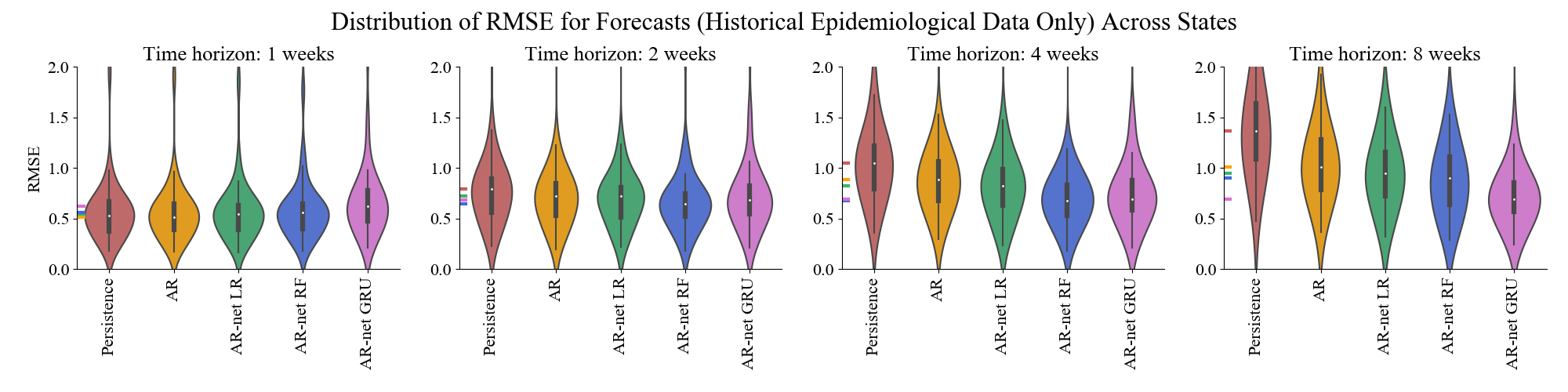
Models
The bulk of the analysis focuses on comparing different supervised machine learning methods for Influenza
prediction. The forecasting methods evaluated are as follows:
- Persistence: This standard baseline for time-series models propagated forward the most
recently observed value for ILI incidence.
- Linear Autoregression - AR(GO): A linear regression mapping 52 autoregressive terms to the predicted
Influenza incidence at a 1-8 week time horizon. Uses L1 regularization for feature selection, with penalty
parameter chosen by 4-fold cross-validation. Nowcasting models also include synchronous Google Trends information for 256 terms.
- Linear Network Autoregression - AR(GO)-net LR: A linear regression mapping 52 autoregressive terms in r regions in the dataset
(with r chosen by 4-fod cross validation) to the predicted Influenza incidence at a 1-8 week time horizon for each region. A
separate model is fitted for each region in the dataset. Uses L1 regularization for feature selection, with penalty
parameter chosen by 4-fold cross-validation. Nowcasting models also include synchronous Google Trends information for 256 terms from
all locations in the dataset.
- Nonparametric Network Autoregression - AR-net RF: Has the same inputs and outputs as the above AR-net LR, but
uses a random forest model with 50 decision trees. Maximum tree depth chosen by four-fold cross-validation.
- Gated Recurrent Unit Neural Network - AR-net GRU: Accepts as input a 52-by-|R| matrix of incidence time series for all regions
in the dataset, and outputs predictions for all regions simultaneously.
Nowcasting methods (denoted ARGO) use the same historic epidemiological data above, plus 1-8 weeks of search query data
obtained from Google Trends (GT). Search query data is obtained for 256 flu-related search terms (chosen in previous
work) on the same geographic and temporal granularity as the epidemiological data.